邵阳整站优化百度销售推广
一、单表查询:
1.基本查询:
1.1 查询多个字段:
1.查询所有字段:
select * from 表名;2.查询指定字段:
select 字段1,字段2 from 表名;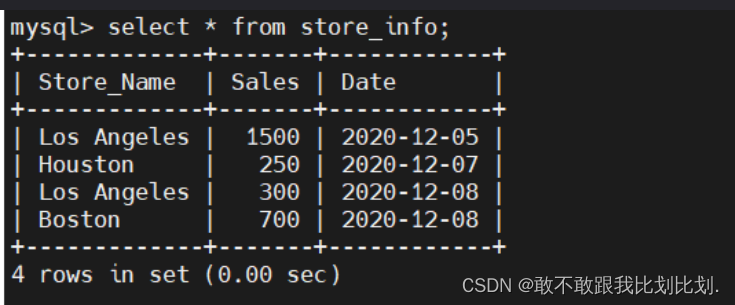
1.2 去除重复记录
select distinct "字段" FROM "表名";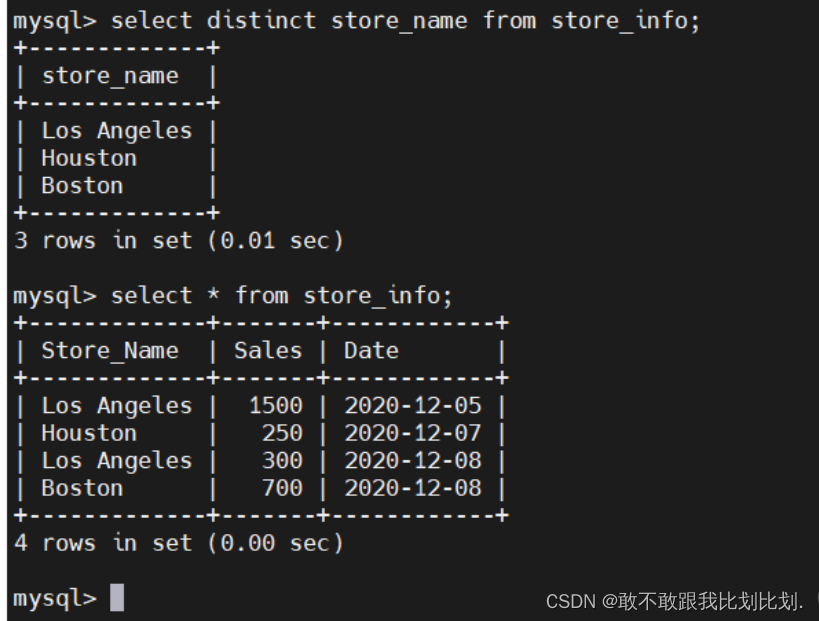
2. 条件查询:
2.1 语法
select '字段列表' from 表名 where 条件;2.2 条件分类:
比较运算符:

between..and..使用示例:

in(..) 使用示例:

like 使用示例:

逻辑运算符:
| and 或 && | 并且 |
| or | 或者 |
| not 或 ! | 非 |
并 使用示例:
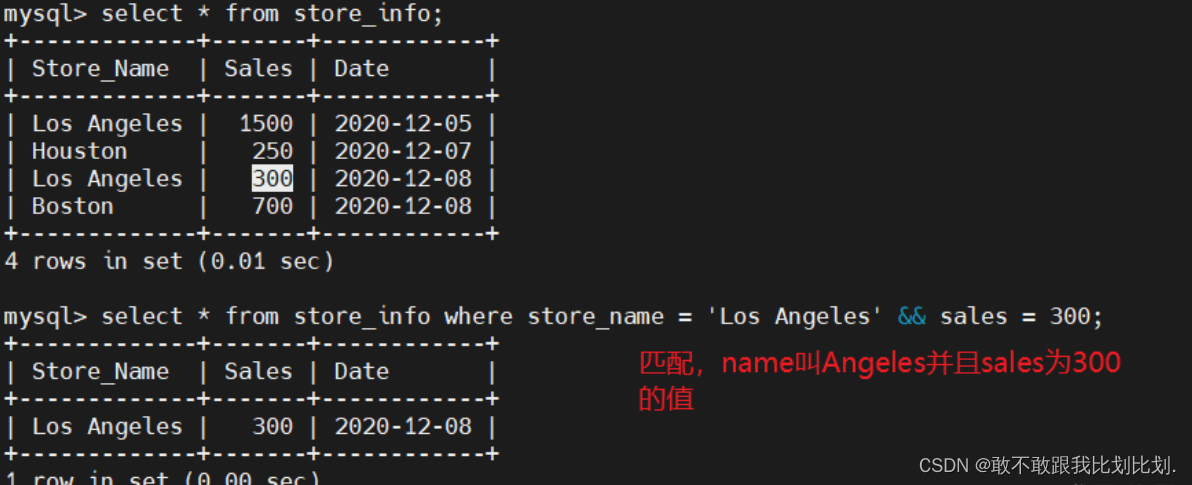
或 使用示例:

3.函数:
3.1 语法:
slect 聚合函数(字段列表) from 表名;3.2 聚合函数:
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
count 使用示例:

sum 使用示例:
 3.3 常用字符串函数
3.3 常用字符串函数
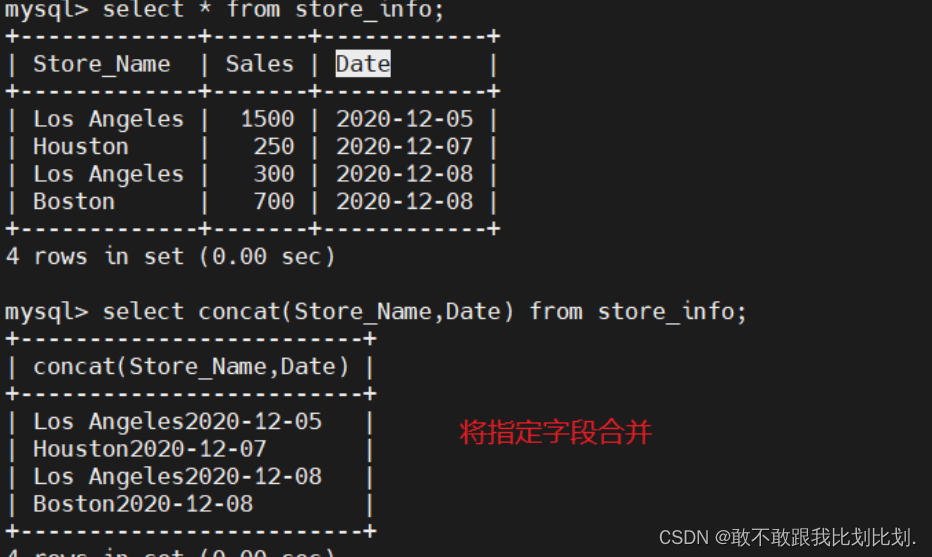
concat(x,y) 将提供的参数 x 和 y 拼接成一个字符串
lower(x) 将字符串 x 的所有字母变成小写字母
upper(x) 将字符串 x 的所有字母变成大写字母
trim() 返回去除指定格式的值
lpad(str,n,pad) 左填充,用pad对str做左边进行填充,达到n个字符长度
rpad(str,n,pad) 右填充,用pad对str做右边进行填充,达到n个字符长度
substr(x,y,z) 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串
concat(x,y) 使用示例:
 trim() 使用示例:
trim() 使用示例:
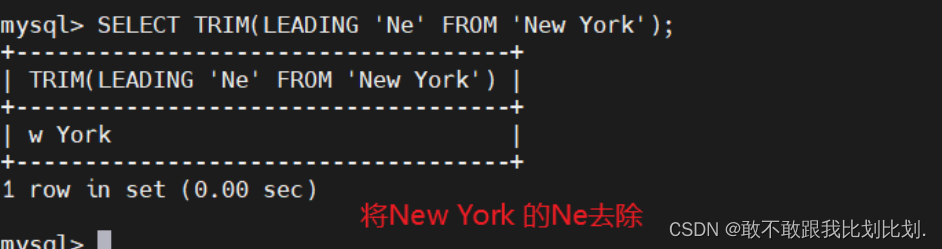
substr(x,y,z) 使用示例:
 3.4 常用数值函数:
3.4 常用数值函数:
| ceil(xx.xxx) | 向上取整 |
| floor(xx.xxx) | 向下取整 |
| mod(x,y) | 返回x/y的余数 |
| rand () | 0-1随机值 |
| round(x,y) | 求x四舍五入的值,y表示保留几位小数 |
ceil(xx.xxx) floor(xx.xxx)使用示例:

3.5 组合使用示例
生成6位数随机密码:

4.分组查询group by:
对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;
4.1 格式:
SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";示例:
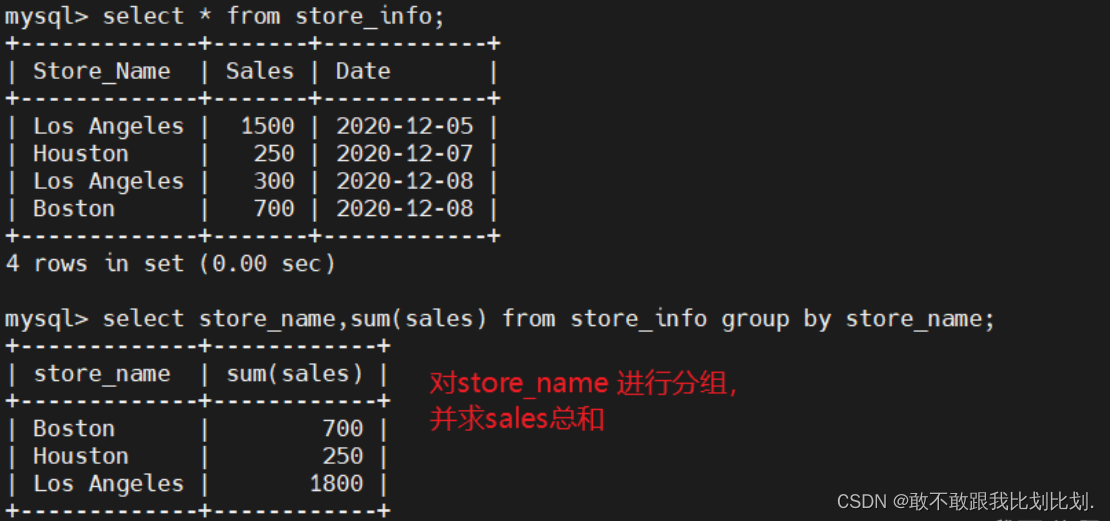
4.2 having:
用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1" HAVING 条件或函数;示例:

5. 排序查询 order by:
ASC 是按照升序进行排序的,是默认的排序方式。
DESC 是按降序方式进行排序。
5.1 格式:
SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
6. 分页查询:
6.1 格式:
select 字段列表 from 表名 limit 起始,查询数;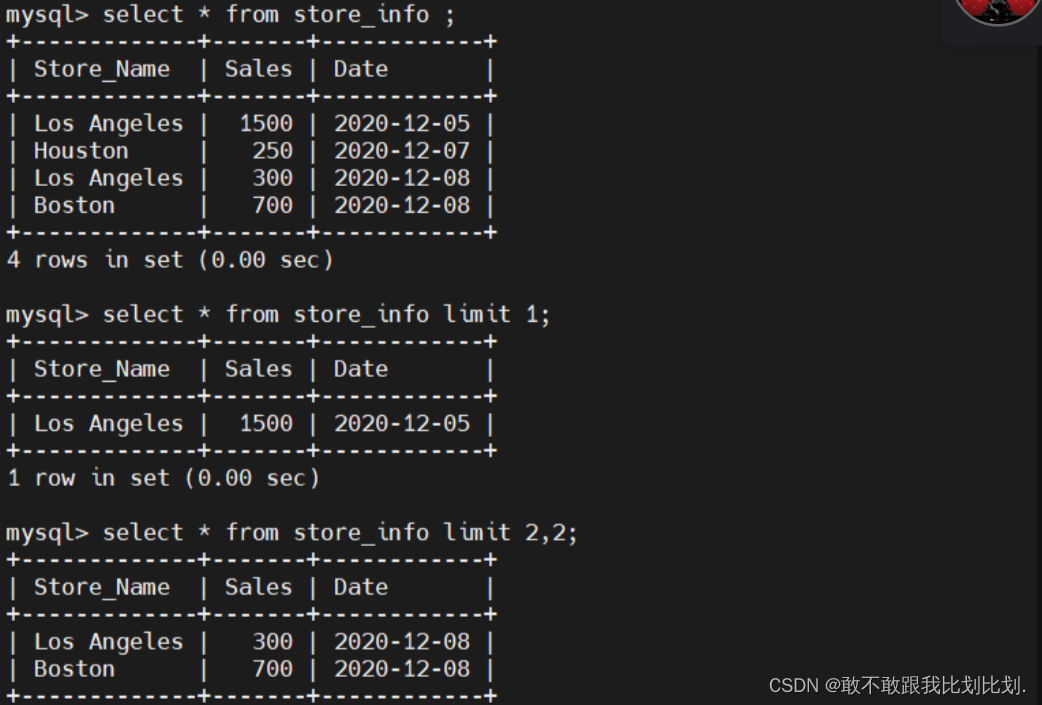
二、连接查询:
1.连接查询分类:
内连接: 只返回两个表中联结字段相等的行
左连接:返回包括左表中的所有记录和右表中联结字段相等的记录
右连接:返回包括右表中的所有记录和左表中联结字段相等的记录
联集: 联集,将两个select查询语句的结果合并,并去重
2.内连接inner jion:
select 查询字段 from 表1 inner join 表2 on 条件;
3. 左连接:
select 查询字段 from 表1 left join 表2 on 条件;
4. 右连接:
select 查询字段 from 表1 left join 表2 on 条件;
5. 联集union:
select 查询字段 from 表1 union select 查询字段 from 表1; #结果合并,并去重select 查询字段 from 表1 union all select 查询字段 from 表1; #结果合并,不去重
6. 左表无交集:
select A.字段 from 左表 A left join 右表 B on A.字段 = B.字段 where B.字段 is null;select 字段 from 左表 where 字段 not in (select 字段 from 右表);7. 求右表无交集:
select B.字段 from 左表 A right join 右表 B on A.字段 = B.字段 where A.字段 is null;select 字段 from 右表 where 字段 not in (select 字段 from 左表);8. 求多表的无交集:
select A.字段 from (select distinct 字段 from 左表 union all select distinct 字段 from 右表) A group by A.字段 having count(A.字段)=1;创建视图,协助查询
create view 视图表名 AS select distinct 字段 from 左表 union all select distinct 字段 from 右表;select 字段 from 视图表名 group by 字段 having count(字段) = 1;
三、视图:
1.介绍:
视图,可以被当作是虚拟表或存储查询。视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
2.格式:
语法:创建:
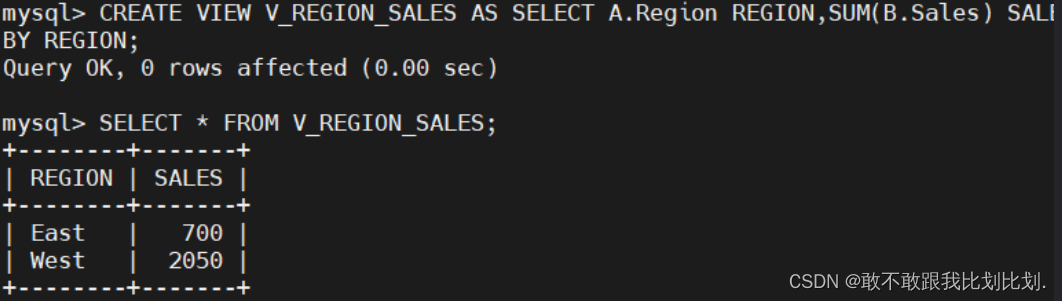
CREATE VIEW "视图表名" AS "SELECT 语句";示例:
CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION,SUM(B.Sales) SALES FROM location A
INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;删除:
DROP VIEW V_REGION_SALES;
四、存储过程:
1.存储过程介绍:
存储过程是一组为了完成特定功能的SQL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
2.存储过程的优点:
1、执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、SQL语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
3.创建存储过程:
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字 BEGIN 开始
-> select * from Store_Info; #过程体语句
-> END $$ #过程体以关键字 END 结束
DELIMITER ; #将语句的结束符号恢复为分号4. 调用存储过程:
##调用存储过程##
CALL Proc;5. 查看存储过程:
SHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息SHOW CREATE PROCEDURE Proc;SHOW PROCEDURE STATUS [LIKE '%Proc%'] \G6. 存储过程的参数:
- IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
- OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
- INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
DELIMITER $$
CREATE PROCEDURE Proc1(IN inname CHAR(16))
-> BEGIN
-> SELECT * FROM Store_Info WHERE Store_Name = inname;
-> END $$
DELIMITER ; CALL Proc1('Boston');delimiter $$
mysql> create procedure proc3(in myname char(10), out outname int)-> begin-> select sales into outname from t1 where name = myname;-> end $$
delimiter ;
call proc3('yzh', @out_sales);
select @out_sales;delimiter $$
mysql> create procedure proc4(inout insales int)-> begin-> select count(sales) into insales from t1 where sales < insales;-> end $$
delimiter ;
set @inout_sales=1000;
call proc4(@inout_sales);
select @inout_sales;
7. 删除存储过程:
DROP PROCEDURE IF EXISTS Proc; #仅当存在时删除,不添加 IF EXISTS 时,如果指定的过程不存在,则产生一个错误8. 存储过程的控制语句:
条件语句:
if 条件表达式 thenSQL语句序列1
elseSQL语句序列2
end if;循环语句:
while 条件表达式
doSQL语句序列set 条件迭代表达式;
end while;如果输入值大于10 id +1 否则 id -1
DELIMITER $$
CREATE PROCEDURE proc2(IN pro int)
-> begin
-> declare var int;
-> set var=pro*2;
-> if var>=10 then
-> update t set id=id+1;
-> else
-> update t set id=id-1;
-> end if;
-> end $$DELIMITER ;创建wzw表并插入10000条数据:create procedure proc5()
begin
declare var int;
set var=1;
create table wzw (id int, name varchar(20));
while var <10000
do
insert into wzw values (var, concat('student',var));
set var = var+1;
end while;
end $$