做国外lead应该做什么网站新东方留学机构官网
此篇文章主要介绍如何使用 Selenium 模块实现 无界面模式 & 执行JS脚本(把滚动条拉到底部),并以具体的示例进行展示。
1、Selenium 设置无界面模式
创建浏览器对象之前,创建 options 功能对象 :options = webdriver.ChromeOptions()
添加无界面功能参数:options.add_argument("--headless")
构造浏览器对象,打开浏览器,并设置 options 参数:
browser = webdriver.Chrome(options=options)
from selenium import webdriver
options = webdriver.ChromeOptions() # 创建浏览器对象之前,创建options功能对象
options.add_argument("--headless") # 添加无界面功能参数
browser = webdriver.Chrome(options=options) # 构造浏览器对象,打开浏览器
2、Selenium 执行JS脚本
创建浏览器对象:browser = webdriver.Chrome()
执行JS脚本:browser.execute_script()
最常用脚本 - 把滚动条拉到底部:browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
from selenium import webdriver
browser = webdriver.Chrome() # 创建浏览器对象
browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
) # 把滚动条拉到最底部
3、Selenium 设置无界面模式 & 执行JS脚本 案例
3.1 需求分析
基于 Selenium + Chrome 抓取 `http://www.jd.com/` 下 “python书籍” 的信息
3.2 爬虫思路
打开浏览器输入主页地址:https://www.jd.com/
使用 Selenium 的 Xpath 找到 信息输入框 和 点击搜索 节点:'//*[@id="key"]' & '//*[@id="search"]/div/div[2]/button'
输入 “python书籍” 并点击 点击搜索按钮;
使用 Selenium 的 Xpath 找到 书籍信息 节点对象列表: '//*[@id="J_goodsList"]/ul/li';
依次遍历每个元素,并依次提取每本书籍信息;
爬取完一页信息后,需要判断是否是最后一页
可以看到:
最后一页的节点信息为:pn-next disabled
非最后一页的节点信息为:pn-next
如果不是最后一页,点击下一页继续进行爬取:'//*[@id="J_bottomPage"]/span[1]/a[9]'
3.3 程序实现
初始化函数
def __init__(self):
# 设置为无界面
self.options = webdriver.ChromeOptions() # 创建浏览器对象之前,创建options功能对象
self.options.add_argument('--headless') # 添加无界面功能参数
self.driver = webdriver.Chrome(options=self.options) # 构造浏览器对象,打开浏览器
self.driver.get(url="http://www.jd.com/") # 进入主页
# 搜索框发送:python书籍,点击搜索按钮
self.inputJD = self.driver.find_element(By.XPATH, '//*[@id="key"]') # 搜索框xpath://*[@id="key"]
self.inputJD.send_keys("python书籍")
self.driver.find_element(By.XPATH,
'//*[@id="search"]/div/div[2]/button').click() # 搜索按钮xpath://*[@id="search"]/div/div[2]/button 并点击
time.sleep(1) # 要给页面元素加载预留时间
提取数据函数
def parse_html(self):
"""
function: 具体提取数据方法
in: None
out: None
return: None
others: Data Extraction Func
"""
self.driver.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
) # 先把滚动条拉到最底部,等待所有商品加载完成再进行数据爬取
time.sleep(3) # 给页面元素加载预留时间
# 具体提取数据
li_list = self.driver.find_elements(By.XPATH,
'//*[@id="J_goodsList"]/ul/li') # 基准xpath://*[@id="J_goodsList"]/ul/li 每一个商品对应一个li节点
item = {} # 定义一个空字典
for li in li_list:
item["名称"] = li.find_element(By.XPATH, './/div[@class="p-name"]/a/em').text.strip()
item["价格"] = li.find_element(By.XPATH, './/div[@class="p-price"]/strong').text.strip()
item["评价"] = li.find_element(By.XPATH, './/div[@class="p-commit"]/strong').text.strip()
item["商家"] = li.find_element(By.XPATH, './/div[@class="p-shopnum"]').text.strip()
print(item) # 打印
程序入口函数
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
while True:
self.parse_html()
# 不是最后一页:pn-next
# 最后一页:pn-next disabled
if self.driver.page_source.find("pn-next disabled") == -1: # 没有找到 pn-next disabled,说明不是最后一页
self.driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]').click()
time.sleep(1)
else:
self.driver.quit()
break
3.4 完整代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class JDSpider:
def __init__(self):
# 设置为无界面
self.options = webdriver.ChromeOptions() # 创建浏览器对象之前,创建options功能对象
self.options.add_argument('--headless') # 添加无界面功能参数
self.driver = webdriver.Chrome(options=self.options) # 构造浏览器对象,打开浏览器
self.driver.get(url="http://www.jd.com/") # 进入主页
# 搜索框发送:python书籍,点击搜索按钮
self.inputJD = self.driver.find_element(By.XPATH, '//*[@id="key"]') # 搜索框xpath://*[@id="key"]
self.inputJD.send_keys("python书籍")
self.driver.find_element(By.XPATH,
'//*[@id="search"]/div/div[2]/button').click() # 搜索按钮xpath://*[@id="search"]/div/div[2]/button 并点击
time.sleep(1) # 要给页面元素加载预留时间
def parse_html(self):
"""
function: 具体提取数据方法
in: None
out: None
return: None
others: Data Extraction Func
"""
self.driver.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
) # 先把滚动条拉到最底部,等待所有商品加载完成再进行数据爬取
time.sleep(3) # 给页面元素加载预留时间
# 具体提取数据
li_list = self.driver.find_elements(By.XPATH,
'//*[@id="J_goodsList"]/ul/li') # 基准xpath://*[@id="J_goodsList"]/ul/li 每一个商品对应一个li节点
item = {} # 定义一个空字典
for li in li_list:
item["名称"] = li.find_element(By.XPATH, './/div[@class="p-name"]/a/em').text.strip()
item["价格"] = li.find_element(By.XPATH, './/div[@class="p-price"]/strong').text.strip()
item["评价"] = li.find_element(By.XPATH, './/div[@class="p-commit"]/strong').text.strip()
item["商家"] = li.find_element(By.XPATH, './/div[@class="p-shopnum"]').text.strip()
print(item) # 打印
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
while True:
self.parse_html()
# 不是最后一页:pn-next
# 最后一页:pn-next disabled
if self.driver.page_source.find("pn-next disabled") == -1: # 没有找到 pn-next disabled,说明不是最后一页
self.driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]').click()
time.sleep(1)
else:
self.driver.quit()
break
if __name__ == '__main__':
spider = JDSpider()
spider.run()
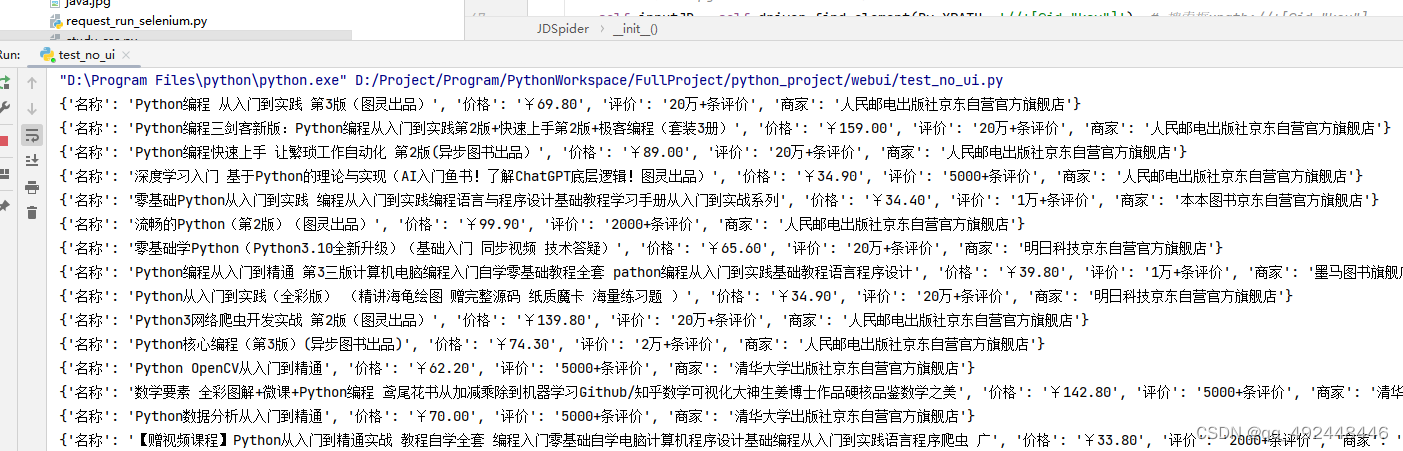
3.5 实现效果